

A Regressão Linear Simples é modelo mais simples de regressão linear. Nela, utilizamos apenas uma variável de desfecho e uma variável preditora. Quando utilizamos mais variáveis preditoras, chamamos de Regressão Linear Múltipla.
Nós temos uma postagem que explica de maneira mais geral os dois modelos de regressão linear e suas diferenças, você pode conferir aqui. Neste artigo, nós vamos focar na Regressão Linear Simples.
Para que serve a Regressão Linear Simples?
Utilizamos a regressão linear simples para descrever a relação linear entre duas variáveis. Com isso, ela é útil em algumas circunstâncias:
- Quando queremos prever o valor de uma variável pelo valor da outra
- Para entender se uma variável está relacionada com a outra
- Criar um modelo base antes de criar modelos de Regressão Linear Múltipla
Como exemplos práticos, podemos:
- Avaliar o coeficiente de inteligência de acordo com a idade
- Entender se “insônia” é um preditor de “depressão”
- Ter como base os valores de regressão para “depressão” prevista por “insônia” para, em seguinte, acrescentar novas variáveis.
Entenda os pressupostos antes de fazer a Regressão!
Nós já falamos sobre os pressupostos da regressão em nosso artigo “O que é Regressão Linear?”. Como os pressupostos são fundamentais para o uso da regressão linear, não custa repetir: os seus dados precisam atender a estes critérios para que a regressão linear seja confiável:
- Linearidade: a relação entre as variáveis deve ser linear.
- Homoscedasticidade (ou Homogeneidade de Variância): os termos de erro variância constante, independente dos valores das variáveis preditoras. Quebramos esse pressuposto quando as variáveis preditoras tem mais ou menos erro dependendo de seus valores.
- Independência de erros. Os erros nas variáveis preditoras não devem estar correlacionados.
- Não multicolinearidade: as variáveis preditoras não podem ser próximas de uma correlação perfeita.
- Baixa exogeneidade: os valores das variáveis preditoras não estão contaminados com erros de medida. Este pressuposto não é muito realista para a Psicometria, mas é importante lembrá-lo, uma vez que erros de medida podem levar estimativas inconsistentes e superestimação dos coeficientes de regressão.
Entendendo a fórmula da Regressão
O coeficientes de uma Regressão Linear Simples nada mais são do que uma equação da reta:

Onde yi são os valores da variável de resultado, o que queremos prever, e xi são os valores da nossa variável preditora. Já o α é o valor do intercepto, que nos informa o valor de “y” quando “x” é zero. O β é o valor que determina a inclinação da reta, o que determina a força da relação entre as variáveis.
Nos gráficos a seguir podemos ver a distribuição de variáveis, e suas retas de regressão. Repare como diferentes valores α e β determinam como será a reta.

Exemplo prático de Regressão Linear Simples
No parágrafo seguinte você verá o relatório da regressão gerado no R, que será muito parecido com relatórios gerados em programas como o SPSS, SAS e JASP. Neste exemplo, tentaremos identificar se há relação entre o Produto Interno Bruto de um país e a média dos scores de felicidade realizados pela Organização Mundial da Saúde.
Na tabela a seguir você verá as medidas de ajuste da regressão. Elas indicam o quão boa a regressão é para a relação observada. Vamos abordar cada um deles na próxima sessão.
Tabela 1: Estatísticas de Ajuste da Regressão Linear Simples
| Erro Padrão Residual | 0,68 (gl = 154) | ||
| R² | 0,63 | ||
| Estatística F | 262,5 (gl = 1 e 154) | p < 0,001 |
Já na tabela seguinte estão os coeficientes necessários para entender a relação entre as variáveis.
Tabela 2: Coeficientes da Regressão Linear Simples: Felicidade e PIB de países
| Estimativa | Estimativa padronizada | Erro Padrão | valor-t | valor-p | |
| (Intercepto) | 3,40 | 0,00 | 0,13 | 25,12 | < 0,001 |
| GDP | 2,22 | 0,79 | 0,14 | 16,20 | < 0,001 |
Agora que fomos formalmente apresentados aos resultados da regressão, vamos entender cada item.
Erro padrão residual (ou Residual standard error)
De maneira simplificada, esta estimativa nos indica o quanto os dados observados se afastam da linha de regressão que foi calculada. Quanto maior for o Erro Padrão Residual (EPR), menor é o ajuste dos dados ao modelo.
A parte “gl = 154” são os graus de liberdade. Ele não nos traz informações relevantes sobre nosso modelo de regressão. No entanto, é importante reportá-lo para que outras pessoas possam recalcular os resultados da sua regressão sem acesso aos seus dados, como em estudos de metanálise.
O RPR não é uma medida padronizada. Isso significa que seus valores seguem os valores originais dos dados usados. Em nosso exemplo, os valores de felicidade vão de 2,85 a 7,80, com uma média de 5,41. Com isso em mente podemos interpretar que um RPR de 0,68 é um erro pequeno.
Dito isso, nos basear em medidas não padronizadas pode levar à erros de interpretação. Seria melhor se tivéssemos uma medida de erro que pode ser interpretada independente dos valores das variáveis. Estas são as medidas padronizadas e o R² é uma delas!
O que é o R²?
O R² é uma medida que nos diz em quantos porcentos o a regressão linear é capaz de explicar a variação dos dados observados. No exemplo fica mais fácil: nosso R² é de 0,63. Com isso, podemos dizer que a regressão é capaz de determinar 63% da variação dos dados.
Não existe uma maneira padronizada de quanto deve ser o valor de R², devemos sempre interpretá-lo com base na teoria sobre nossas variáveis. Para fins de exemplo, podemos considerar que 63% da variação de felicidade poder ser explicada pelo PIB é um efeito grande.
A estatística F
Por mais que nosso R² tenha um efeito grande, também precisamos olhar o valor de significância da estatística F. Ele nos indica se o nosso modelo é significativamente diferente um modelo nulo.
No caso da Regressão Linear Simples, o modelo nulo é um modelo de regressão onde a variável preditora é a média da variável de resultado. Ou seja, se nosso modelo não for suficientemente diferente da uma constante, significa que não é um modelo muito bom.
Tendo isso em mente, devemos olhar se o valor de significância do F é menor do que 0,05. No nosso exemplo, o valor é menor do que 0,001. Então podemos confiar na nossa regressão.
Na Regressão Linear Simples, a estatística F nos dá a mesma informação que os valores de do teste-t, que veremos adiante. Na verdade, o valor de F será o valor de t ao quadrado. Mas como isso não se aplica a regressões múltiplas, que comumente é usada junto da regressão simples, é importante saber interpretá-lo.
O que preciso analisar no valor de p e t?
Agora podemos voltar nossa atenção à tabela 2. A primeira coisa que devemos olhar é se o valore-p é significativo para nossa variável de interesse (PIB). Valores menores que 0,05 indicam que a inclusão daquela variável faz com que o modelo seja significativamente diferente de um modelo nulo.
O valor-p é calculado à partir do valor do teste-t, coluna ao lado. Por isso, não é necessário analisar os valores brutos de t, mas é importante relatá-los para que o resultado seja transparente.
Como interpretar os coeficientes β?
Indo para o início da tabela 2, na coluna estimativa estão os valores do intercepto (3,40) e do coeficiente β, associado à variável PIB (2,22). Estes são os valores que indicam a linha estimada pela regressão. Sabemos que a linha cruza o eixo x com valores de Y de 3,40. Isso indica que um país com um PIB (fictício) de 0, teria um valor basal de felicidade de 3,40.
Já o coeficiente β indica o quanto aumenta a felicidade conforme aumenta o PIB. Interpretamos assim: se aumentarmos uma unidade no valor do PIB, aumentamos 2,22 no escore médio de felicidade.
Talvez você entenda melhor olhando o gráfico de pontos a seguir. A linha azul representa a nossa estimativa de regressão. A linha verde pontilhada significa o caminho que vamos fazer.
Quando aumentamos os valores do PIB em uma unidade, “andando” para a direita no eixo x, seguindo a linha azul, estamos aumentando o valor no eixo y em 2,22.
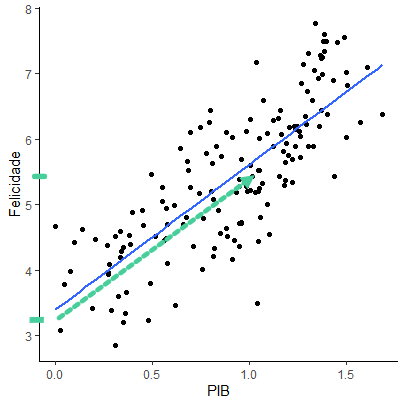
β padronizado
Mas o aumento de 2,22 nos índices de felicidade é um efeito grande ou pequeno? Para termos uma interpretação mais fácil, podemos olhar os valores de β padronizado (βp), na coluna seguinte da tabela 2.
Na Regressão Linear Simples, os valores do βp são idênticos ao de uma correlação. Então se você já leu nosso artigo sobre correlação, você já sabe como interpretá-lo.
Outro atalho para o βp na Regressão Linear Simples, é que se o elevarmos ao quadrado, ele é idêntico ao R². O que significa que podemos interpretá-lo de acordo com a porcentagem que esta variável (PIB) impacta no resultado (Felicidade). Assim: 0,79² = 0,63 = 63%. Logo, o PIB explica 63% da variação de felicidade na nossa amostra.
Sem recorrer a atalhos, os valores de βp estarão entre -1 e 1. Valores próximos a zero significam que há pouca relação entre a variável de resultado e a preditora. Valores próximos a 1 indicam que há uma relação forte entre resultado e preditor.
Já os valores próximos a -1 também indicam uma relação forte, mas no sentido contrário: aumentar o valor do preditor, diminui o valor da variável de resultado.
Erro Padrão
Nossa última métrica é o erro padrão. Ele indica, de maneira simplificada, o quanto a estimativa daquele coeficiente está distante da média da população. Desta forma, quanto menor o valor do erro padrão, mais representativa é aquela variável. Outro ponto importante é que o erro padrão pode ser usado para calcular intervalos de confiança.
Regressão Linear Simples vs. Correlação de Pearson
Como eu disse, o βp na Regressão Linear Simples traz os mesmo valores que o r de Pearson. Se você estiver na dúvida de qual usar, a Regressão Linear Simples é mais adequada quando:
- O desenho da pesquisa envolve modelos de Regressão Linear Múltipla, de forma que fica mais simples relatar uma Regressão Linear Simples ao invés da correlação de Pearson.
- A Regressão Linear Simples servirá como ponto de partida para a inclusão de mais variáveis posteriormente.
- Você não está interessado nos coeficientes padronizados, quer saber os resultados de acordo com os valores da sua variável.
- Você está interessado em saber a equação da reta.
- Você está interessado no valor do intercepto.
- Você quer prever novos valore da variável de resultado, mas só tem os valores da variável preditora.
Por outro lado, a correlação de Pearson é mais simples de ser realizada e é mais adequada para a maioria dos casos onde não haverá a inclusão de outras variáveis.
Conclusão
Com este artigo, espero que você consiga interpretar com maior facilidade os resultados de um regressão, sabendo como interpretar os coeficientes, as medidades de ajuste e como a variável preditora impacta a variável de resultado.
Você também deve estar pronto para o próximo passo: a Regressão Linear Múltipla, que nada mais é do que uma extensão da Regressão Linear Simples onde usamos várias variáveis preditoras.
—
Gostou desse conteúdo? Precisa aprender Análise de dados? Faça parte da Psicometria Online Academy: a maior formação de pesquisadores quantitativos da América Latina. Conheça toda nossa estrutura aqui e nunca mais passe trabalho sozinho(a).








Uma resposta